
This article summarizes some lower level aspect of how GPU executes. Although GPU programming is not that complicated when compared to CPU, it also doesn’t match to what hardware is doing exactly. The reason is that we can’t just program GPU without some API, which is an abstraction over its inner workings. Since few years now, we have modern explicit APIs like DirectX 12 or Vulkan, which shrunken the gap to what is happening with hardware. Yet there still are few low-level bits (pun intended) that are worth explaining.
Note from author: although this post is not about any graphics or compute API, I will use some names that come from Vulkan, mainly because it’s the only modern and multi-platform API out there.
Parts of GPU - quick recap
Let’s list most important parts of GPU at the lowest possible level:
- FP32 units
- FP64 and/or SPU (Specialized Procesing Unit)
- INT32 units
- Registers
- on-chip memory:
- L0$ (rarely in consumer class hardware)
- L1$ used with Shared Memory per compute unit
- L2$ per GPU
- off-chip memory (device memory)
- instruction scheduler
- instruction dispatcher
- TMUs, ROPs - fixed pipeline units
- …and more
All mentioned above are grouped into many hierarchies, of course, that make our graphics cards in the end.
GPU is one big async-await mechanism
At least that’s how you can think about it from CPU point of view. It’s of course much more complicated than anything you can see in CPU side. But still, logic stays. You dispatch some work and await for the results while doing other stuff. You need to ensure some synchronization to whether something is done or not. Fence in Vulkan is the primary mechanism to sync CPU and GPU.
Core in GPU
Well, this might be a surprise for many, but so-called cores in GPUs world are more of a marketing term. Reality is much more complicated. CUDA cores in Nvidia cards or just cores in AMD gpus are very simple units that run float operations specifically.1 They can’t do any fancy things like CPUs do (e.g.: branch prediction, out-of-order execution, speculative execution/data fetch). At the same time, they can’t run independently. They are tied to a bunch of neigbours (more on that in # Scalar vs Vector paragraph). Let’s call them shading units from now on. Although some can consider them as a very primitive core that can’t run on its own, we should also mention a much bigger hardware construct that encompasses many of such cores: compute unit. This one has a lot more features that usual core of CPU comprise like caches, registers, etc. There are also some GPU specific elements, such a scheduler, dispatcher, ROP, TMUs, interpolators, blenders and many more. While this can resemble CPUs in some ways, at the end of the day neither shading unit nor compute unit should be considered core, as we know from CPU. Shading unit is just too simple, but compute unit is much more.
Every vendor has its own naming for compute unit:
- Nvidia uses SM (Streaming Multiprocessor)
- AMD uses CU (Compute Unit) and WGP (Workgroup Processor since RDNA architecture)
- Intel uses EU (Execution Unit) and Xe Core (starting from new Arc architecture)
It’s worth mentioning that since Turing architecture there are also 2 new kind of cores: RT Cores and Tensor Cores (AMD has its own RT Cores since RDNA2 architecture too). RT Cores accelerate BVH (Bounding Volume Hierarchy)2 while Tensor Cores speed up FMA operations on matrices with lower precisions (we can usually neglect 32bit floats for machine learning).
You can use RT Cores in both AMD and Nvidia cards by raytracing multi-vendor extensions.
You can use Tensor Cores in Nvidia GPUs directly by VK_NV_cooperative_matrix. It operates on either 32bit or 16bit floats.
If you are curious about amount of SMs on your GPU and you want use this information in your code then there are few options (at least on Nvidia GPU):
- VkPhysicalDeviceShaderSMBuiltinsPropertiesNV
- NVML library - Nvidia library shipped with drivers but C header is distributed with CUDA SDK
Concurrency vs Parrallelism
Now that we know what compute unit consists of, let’s talk about 1 misconception that happens within it. I find concurrency and parallelism interchangeable too easily in many articles. In general SPMT (Single Program Multiple Threads) approach doesn’t let us make any use out of this difference - GPU vendors don’t expose what is inside SM/CU (with small exception to shared memory size and workgroup size), especially how many shading units are there. That’s the main reason why using those words interchangeably doesn’t make any difference from shader writer point of view. But let’s shed some light on what is actually happening when dispatching work to GPU. We will use a diagram of Streaming Multiprocessor from Nvidia’s Turing architecture: 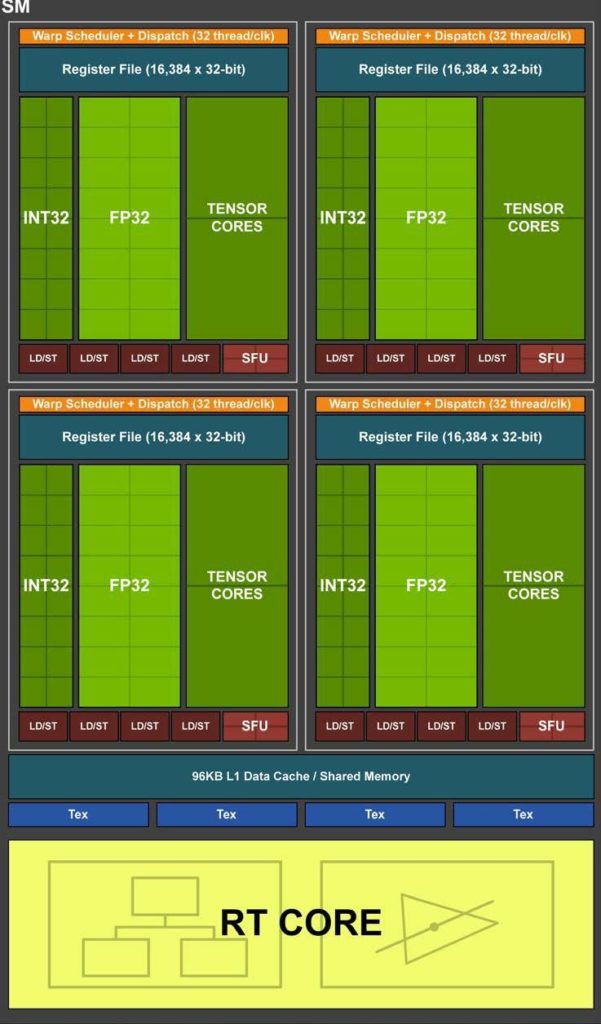
As you can see, each one of such SM has 64 FP32 shading units. At the same time, look at how big registers are. Now let’s use a little contrived example and assume we dispatch work of 4 independent Subgroups (128 threads) containing single precision floating numbers only. First and second Subgroup (64 threads) can execute in parallel because there are enough hardware shading units to cover them. Third and forth will be fetched into register and wait until previous is done/stalled. If stalling is the case, third and forth will be executed concurrently to first and second. It might happen of course that e.g. only 2nd Subgroup will stall, then 1st and 3rd might execute in parallel. This distinction does not give you any advantage when writing code in most cases, but it should be clear now that both - parallel and concurrent - cases happen on GPU and mean different things.
If you are coming from CPU world, then concurrency on GPU is a similar concept to SMT and Hyper Threading but with different scale.
Smallest unit of work
Once we prepare our data, we can dispatch it into Workgroup. Workgroups are construct that encompass at least 1 unit of work (that matches to 1 hardware thread) that is submitted as a one. It can be 1 operation or thousands. But for GPU, it doesn’t matter how much of data we provide because it’s all split into groups that match underlying hardware…
Smallest unit of execution is not smallest unit of work
…and those groups have different names per vendor:
- Warp - on Nvidia
- Wave(fronts) - on AMD
- Wave - when using DX12
- Subgroup - when using Vulkan (since 1.1)
Subgroups length varies per hardware supplier. AMD had 64 floats on Vega cards and now with Navi, it uses 32/64 combination. Nvidia uses 32 floats. Intel, on the other hand, can operate in 8/16/32 configurations.3 Those Subgroup sizes are crucial to understand the difference: while the smallest unit of work is indeed a 1 thread, our GPU will run at least workgroup size of threads to execute it! It might sound suboptimal to say at least, but given GPUs are made for a huge amount of data, this is actually very fast. All not optimal data combinations that don’t match Subgroup perfectly are mitigated by a mechanism called latency hiding.
It’s also worth mentioning that we do process data in chunks because raster units output data as quads (not separate pixels) and historically GPUs were only able to process graphics pipelines. Quads are needed for derivatives which are used by samplers later on (not going much into detail: we can use mip-mapping thanks to this pipeline). Nowadays hardware producers strive to balance the size of subgroup because:
- smaller subgroups means smaller divergence cost but also reduced memory coalescence (efficiency)
- bigger subgroups means costly divergence but increase memory coalescence (flexibility)
Register file vs cache
But before we describe what latency hiding is, we need to understand 1 crucial hardware aspect: register size. If there was only 1 fact that I can use to let somebody understand the difference between GPU and CPU it would be this: on GPU register file is bigger than cache! Let’s use an example of RTX 2060 from Nvidia. Per every SM there is a register of size 256KB, meanwhile L1/shared memory per this exact SM is only 96KB.
Latency hiding
Knowing how big are GPU registers, we can now understand how it is that GPUs are so efficient with a truckload of data. Most of the work is executed concurrently. Even if just 1 thread in Subgroup must wait for something (e.g.: memory fetch) then GPU does not wait for it. Whole Subgroup is marked as stalled. Another eligible Subgroup is executed from the pool of Subgroups stored in registers. As soon as the previous one finishes the operation that stalled it, it’s re-run once more to finish the job. And in real case scenarios, it happens with thousands of Subgroups. Ability to switch immediately to another Subgroup if we wait for something (latency) is crucial to GPU. It hides the wait times by rolling another set of eligible Subgroups.
Some nomenclature:
- active Subgroup - one that is being executed
- resident Subgroup/Subgroup in flight - it’s stored in registers
- eligible Subgroup - it’s stored in registers and marked as ready to run or re-run
Occupancy
Short version: ratio of how good we saturate our GPU.
Occupancy is not how good we utilize GPU! It’s how many resident Subgroups are there (opportunities to hide latency). ALUs can be stressed to the max even with low occupancy, though in that case we will lose good utilization fast.
Long version: let’s assume that some compute unit can have 32 resident Subgroups (full capacity of register file). Now let’s dispatch 32 fully independent Subgroups of work to saturate it fully. Given 32 possible Subgroups even if 31 are stalled, we still have opportunity to hide latency by executing 32nd. This is basically it: ratio of how many independent Subgroups you dispatched per all possible Subgroups in-flight.
Now let’s assume you dispatch 8 shaders, each using 128 threads (covers 4 Subgroups in hardware). But this time these shaders need to be treated together (if they would be fully independent, then driver will split those in 4 separate Subgroups effectively creating exactly the same situation as above). In other words, every thread this time needs 4 registers. Our compute unit stays the same, so it still has only 32 possible Subgroups in flight. What happens now is that there are 4 times less possibilities to hide latency (switch to another 4 Subgroups) because every Workgroup is now 4 times bigger. This means our occupancy is only at 25% right now. There is important notion to remember here: increased register usage per Subgroup decreases overall occupancy. Of course, unless you have very well structured data, shaders that need to be dispatched almost never ends with 100% occupancy levels. Taking it to extreme: if you dispatch 1 big shader that fills whole register size of compute unit, then there is nothing to switch when something stalls (no latency hiding possibilities).
Register Pressure and Register Spilling
Let’s take the previous example even further. What if every thread needs even more register space? Every time we increase thread requirements measured in register space needed, we also increase register pressure. Low register pressure is nothing to worry about, we will just decrease occupancy (which is also not bad until there is always work to hide latency). But as soon as we start increasing register usage per thread, we will inevitably hit pressure level that driver might consider spilling. Register spilling is the process of moving data that should normally be stored in registers into L1/L2 cache and/or off-chip memory (device memory in Vulkan). Driver might decide to do so if occupancy is really low to maintain some hiding latency opportunities at the cost of slower memory access.
As a side note: while spilling to on-chip memory may actually increase performance4 this is less obvious in spilling to off-chip memory.
Scalar vs Vector
One of previous paragraph stated we can’t execute work smaller than workgroup size. There is actually more to that. AMD hardware is a vector in nature. That means it has separate units for vector operations and scalar operations. Nvidia on the other hand is scalar in nature which means Subgroups can handle a mix of other types (mostly combination of F32 and INT32). Wait, so the previous paragraph was a lie and we can actually execute work smaller than Subgroup? Correct answer is: we can’t, but scheduler can. Dividing work that needs to be executed is up to scheduler. It also does not change a fact that scheduler will still take scalars amount of at least Subgroup size, it just won’t use it for anything. In the same scenario, AMD must use whole vector but not needed operations will be zeroed and discarded.5 Intel takes this solution one step further even, as vector size can really vary!
From our perspective, previous paragraphs still hold. Unless you are doing micro-optimizations of your data layout that is fed to GPU, the difference can be neglected. AMD approach should give really good results if data is well structured. For more random data, Nvidia would probably take a lead.
Using types non native to hardware
We have two cases here:
- Using types bigger that common native size
- Using types smaller than common native size
Most consumer-class GPUs use 32 float units as the most common native size. So what happens if we use double precision float (64 bit)? Unless there are too many of those dispatched at the same time, nothing bad happens other than highest register usage (registers in GPUs use 32bit elements, so 64 floats take 2 of those). Most graphics vendors provide separate F64 units or Special Purpose units to handle more precise operation.
Using smaller than native sizes is more interesting. First, we actually may have hardware that can handle those (at least nowadays). Second lower precision floats are in high demand since few years now. Not only because of machine learning but also for game specific purposes. Turing is very interesting architecture here as it splits GPUs to GTX and RTX variants. The former doesn’t have RT cores and Tensor cores, while the latter has both of those. RTX’s Tensors are special FP16 units that can also handle INT8 or INT4 types. They are specialized in FMA (Fused Multiply and Add) matrix operations. Main purpose for Tensor cores is to use DLSS6 but I’m blindly guessing here that driver can decide to use them for other operation as well. GTX version of Turing architecture (1660, 1650) has no Tensor cores, instead it has freely available FP16 units! They are no more specialized in matrix ops, but scheduler can use them at whim if needed.
16bit-sized floats are also known as half-floats.
What happens if we use F16 on GPU that doesn’t have hardware equivalent, neither by Tensor core nor separate FP16 units? We still use FP32 units to handle and what’s more important, we would waste register space because no matter the size of our type we still put it in 32bit element. But there is 1 big improvement also: decreased bandwidth.
Branching is bad, right?
You probably heard it many times but the correct answer is: it depends. When somebody is talking about branching in a negative way, he or she means it’s happening within Subgroup. In other words intra-subgroup branching is bad! But this is only half of the story. Imagine you are running Nvidia GPU and dispatching 64 threads of work. If 32 consecutive threads end in 1 path while other 32 end in another, then branching is perfectly fine. In other words inter-subgroup branching is totally fine. But if only one thread will branch within those 32 packed floats, then other will wait for it (marked as inactive) and we end with intra Subgroup branching.
L1 cache vs LDS vs Shared Memory
Depending on nomenclature you can see LDS (Local Data Storage) and Shared Memory - they actually both denotes to exactly same thing. LDS is a name used by AMD while Shared Memory is term coined by Nvidia.
L1$ and LDS/Shared Memory are different things but both occupy same space in hardware. We don’t have any explicit control over L1 cache usage. It’s all managed by the driver. The only thing we can program is Local Data Storage that shares space with L1 cache (with configurable proportions). Once we start using shared memory, we may step into some problems…
Memory Bank conflicts
Shared memory is divided into banks. You can think of banks as orthogonal to your data. How each bank is mapped to memory access depends on a number of banks and size of word. Assuming 32 banks with 4-bytes long word - if you have an array of 64 floats then only 0th and 32nd element will end in bank1, 1st and 33rd will end in bank2, etc. Now if every thread from Subgroup is accessing unique bank, then this is ideal case scenario as we can do it in one load instruction. Bank conflict occurs if 2 or more threads are requesting different data from single memory bank. This means that access to those data cells needs to be serialized, which is just pure evil. In the worst-case scenario, you can end with all threads accessing one memory bank but fetching 32 different values - which effectively means that it could take 32 times more time.7
Accessing particular value from the same bank by many threads is not a problem. Let’s take it to the extreme: if all threads access 1 value in 1 bank then it’s called broadcasting - under the hood it’s only 1 shared memory read and this value is broadcasted to all threads. If some (but not all) threads access 1 value from a specific bank, then we have multicast.
Some examples:
- Optimal shared memory access:
1
2
3
4
5
//evenly spread
arr[gl_GlobalInvocationID.x];
//not evenly spread but each thread is accessing different bank
arr[gl_GlobalInvocationID.x * 3];
- Bank conflict:
1
2
3
4
5
//"double" conflict
// - when multiplying by 2
// - when using doubles
// - when using struct of 2 floats
arr[gl_GlobalInvocationID.x * 2];
- Broadcast:
1
2
arr[12]; //constant based
arr[gl_SubgroupID] //variable based
Due to latency hiding and shared memory speed, bank conflicts might actually be irrelevant. Until some Subgroup figures out conflicting access, scheduler can switch to another one.
Bank conflicts may happen only within Subgroups! There is no such thing as bank conflict between Subgroups.
Register Bank conflict may arise as well.
Shader process compilation is similar to… Java
What? Modern APIs like Vulkan and DX12 let us offload shader compilation from running graphics/compute application. We compile GLSL/HLSL into SPIR-V beforehand and keep it as an intermediate representation (bytecode) only to be later consumed by driver. But driver takes it (possibly with last-minute changes - like constant specialization) and compiles it once more to vendor and/or hardware specific code. Logic here is very similar to what happens with managed languages like C# or Java, where we compile our code into IL, which is then compiled/interpreted by CLR or JVM on particular hardware.
Instruction Set Architecture
If you want to go deeper, how does GPU execute instruction sets are really excellent read. There are 2 companies that shares ISAs freely for theirs particular hardware:
Bonus - Linux vendor drivers names
My main OS is Linux for over 6 years now. As always, driver situation can surprise many people coming from Windows so let’s dive in into complicated political situation of Vulkan drivers.
For the Nvidia we have 2 choices:
- nouveau - usable for usual day to day job like office or watching youtube but not gaming or computing, development hindered by some Nvidia decissions
- Nvidia proprietary driver - way to go in most cases, works flawlessy but without code access
AMD:
- AMDVLK - open source version
- Mesa 3D - 3D library that provides open source radv driver, most popular choice when it comes to AMD
- AMD Proprietary AMDGPU-PRO
Intel:
- Mesa 3D - similarly to AMD, driver is open and part of this library
Footnotes
What RT Core does is actually BVH traversal, box intersection test, triangle intersection test and unlike all other execution patterns in GPU, which are SIMD-alike, RT core is MIMD type inside. ↩
Newer architectures - for example Turing - can have separate execution cores for int32 type ↩
This flexibility results in really interesting advantage over AMD and Nvidia ↩
If shared memory/L1 or L2 caches are under-initialized ↩
AMD usually compensates this architectural choice by using bigger registers and caches. ↩
Deep Learning Super Sampling can be misleading. While you can use Tensor Cores for deep learning, what happens during a running game is merely inferencing from already generated data. This data is not computed on our GPU, but rather inside nexus of connected Nvidia beefy accelerators and later stored inside driver blobs. ↩
This situation might be mitigated by having many LD/ST units per scheduler that can dispatch more than 1 instruction per cycle (the more the merrier) ↩